We present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation.

ImageNet3D
Motivation
Despite the importance of object-level 3D understanding, previous datasets in this area were limited to a very small number of categories
We consider two types of unified 3D models.
- (i) Pretrained vision encoders with object-level 3D awareness. Vision encoders from MAE
, DINO , CLIP , etc. are pretrained with self-supervised or weakly-supervised objectives. By learning a 3D discriminative representation, these vision encoders can be integrated into vision systems and benefit downstream recognition and reasoning. While these encoders are found useful for 3D-related dense prediction tasks , their object-level 3D awareness remains unclear. - (ii) Supervised 3D models. By training on a large number of diverse data with 3D annotations, these models may achieve a stronger robustness and generalization ability. However, there has been a lack of large-scale 3D datasets with a wide range of rigid categories, which constrains us from developing large unified 3D models for rigid objects or study the generalization and emerging properties of these models.
Overview
We choose the ImageNet21k dataset
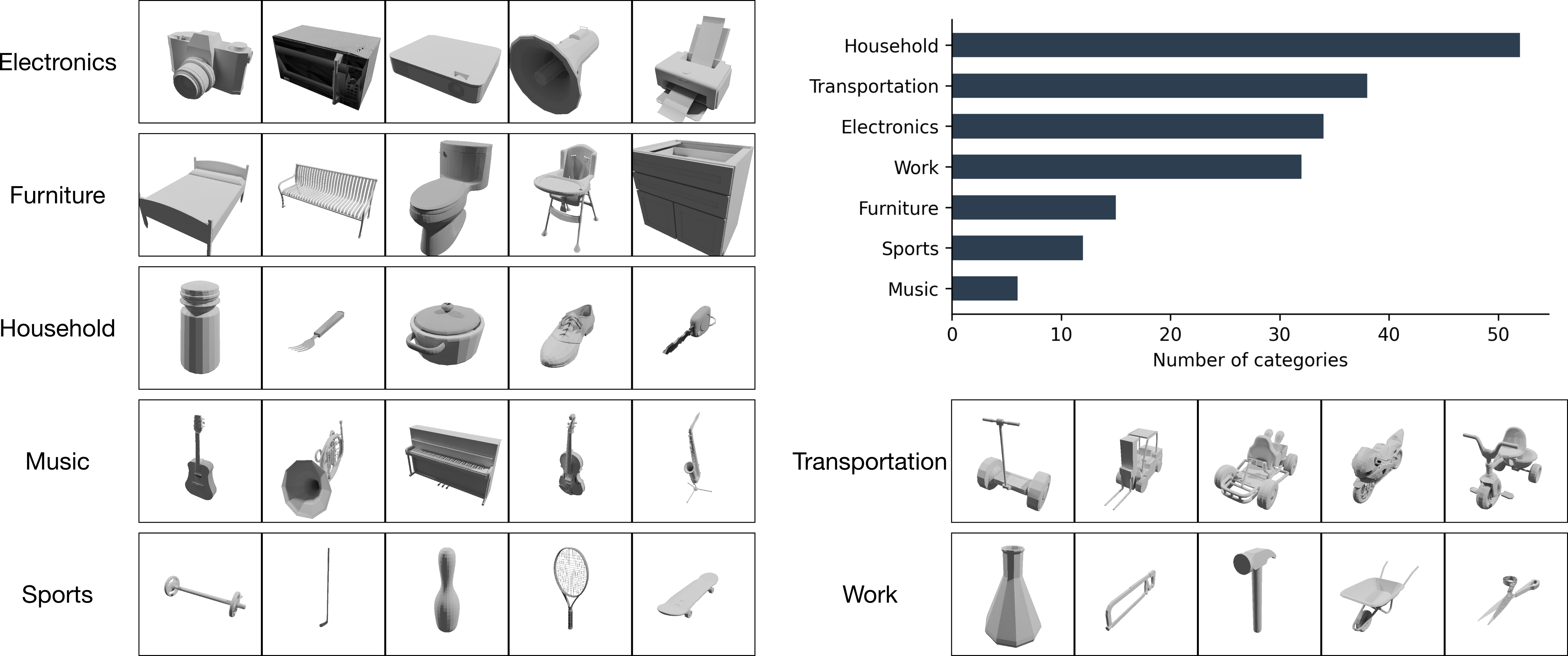
Our dataset features three key designs: (i) a large-number of categories and instances, (ii) cross-category 3D alignment, and (iii) natural captions interleaved with 3D information.
Cross-Category 3D Alignment
In previous datasets such as ObjectNet3D
We manually align the canonical poses of all 200 categories in ImageNet3D, based on the following three rules: (i) semantic parts, (ii) similar shapes, and (iii) common knowledge.

Natural Captions with 3D Information
An important application of general-purpose object-level 3D understanding models is to integrate them with large language models (LLMs) and benefit downstream multi-modal reasoning. Hence we present image captions interleaved with 3D information, which can be used to develop multi-modal large language models (MLLMs) with 3D reasoning capabilities similar to previous approaches
We adopt a GPT-assisted approach to produce natural captions with 3D information. By feeding our 2D and 3D annotations via the textual prompts, GPT-4v would integrate these information and produce a coherent image caption interleaved with 3D annotations represented by a special <pose6D> token.
Tasks
Besides standard 3D/6D pose estimation and image classification as studied in prior worksLinear Probing of Object-Level 3D Awareness
Recent developments of large-scale pretraining have yielded visual foundation models with strong capabilities. Self-supervised approaches such as MAE
We evaluate object-level 3D awareness by linear probing the frozen feature representations on 3D viewpoint classification task. Specifically, three linear classifiers are trained with respect to each of the three parameters encoding 3D viewpoint.
We compute pose errors given by the angle between the predicted rotation matrix and the groundtruth rotation matrix
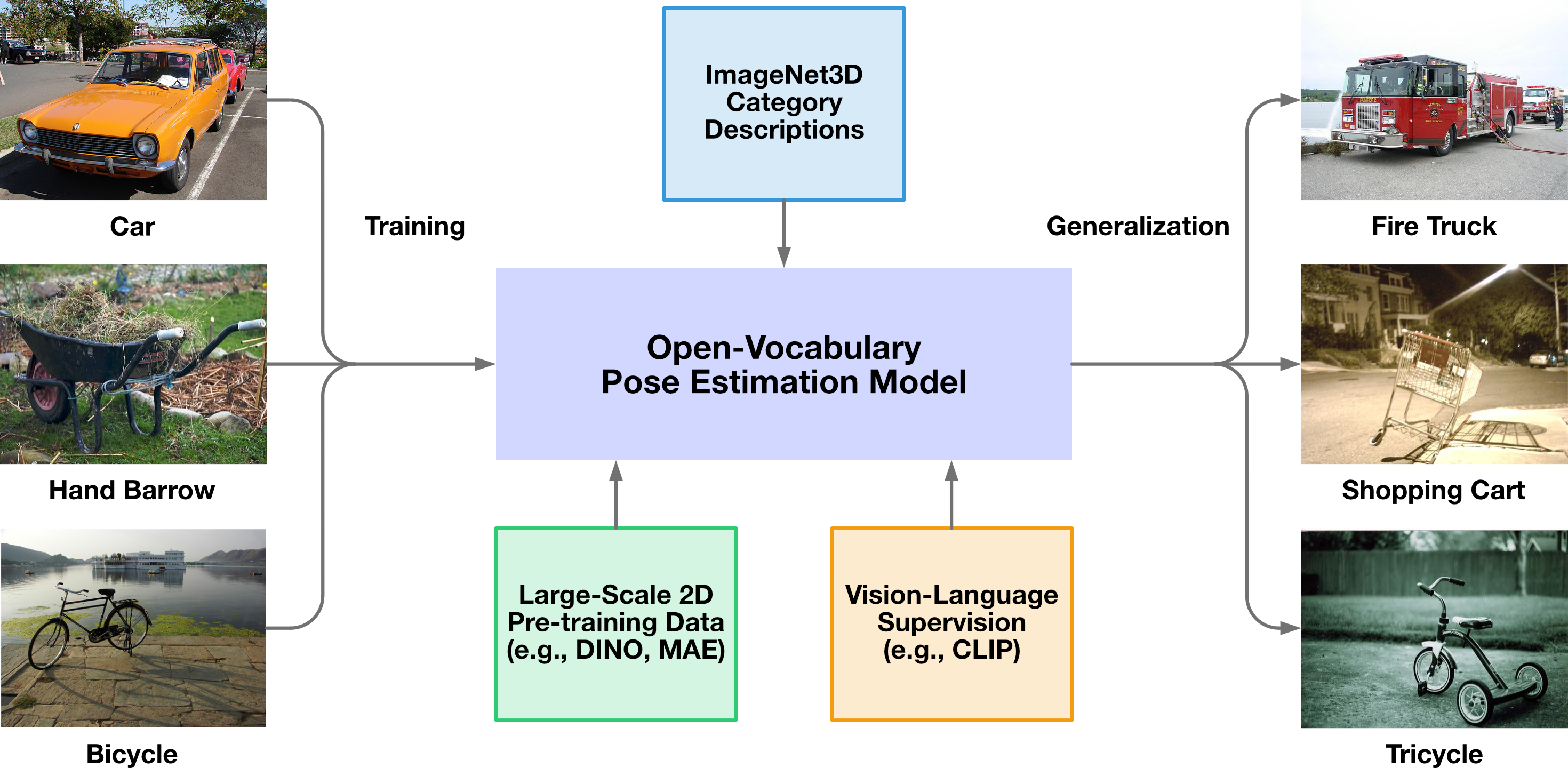
Open-Vocabulary Pose Estimation
In this setting, we study how 3D models generalize to novel categories. Models may utilize semantic parts that are shared between novel categories and categories that are seen during training. Additionally, open-vocabulary pose estimation models may utilize large-scale 2D pre-training data or vision-language supervision and learn useful semantic information. Lastly we provide detailed descriptions of object shape, part structure, and how humans interact with these objects for all categories in ImageNet3D.
Baseline Results
Task 1: Linear Probing of Object-Level 3D Awareness
We measure the object-level 3D awareness for a range of general-purpose vision models designed for representation learning
| Model | Arch | Supervision | Dataset | Pose Accuracy @ pi/6 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg. | Elec. | Furn. | Hou. | Mus. | Spo. | Veh. | Work | ||||
| DeiT III |
ViT-B/16 | classification | ImageNet21k | 36.6 | 47.9 | 48.2 | 36.8 | 21.5 | 16.6 | 35.0 | 25.3 |
| MAE |
ViT-B/16 | SSL | ImageNet1k | 46.6 | 57.6 | 67.8 | 40.2 | 29.0 | 20.2 | 58.4 | 25.6 |
| DINO |
ViT-B/16 | SSL | ImageNet1k | 42.0 | 53.1 | 57.0 | 39.8 | 28.0 | 19.3 | 45.3 | 27.0 |
| DION v2 |
ViT-B/14 | SSL | LVD-142M | 56.3 | 64.0 | 75.3 | 47.9 | 32.9 | 23.5 | 74.7 | 38.1 |
| CLIP |
ViT-B/16 | VLM | private | 39.7 | 50.3 | 52.8 | 39.7 | 23.1 | 19.3 | 39.8 | 26.4 |
| MiDaS |
ViT-L/16 | depth | MIX-6 | 40.5 | 50.9 | 56.7 | 40.2 | 26.7 | 18.9 | 39.2 | 28.1 |
Task 2: Open-Vocabulary Pose Estimation
For baseline results, we consider models that learn category-agnostic features that generalize to novel categories and instances. Specifically, we consider (i) classification-based methods that formulate pose estimation as a classification problem, and (ii) 3D compositional models that learn neural mesh models with contrastive features and perform analysis-by-synthesis during inference. The implementation of 3D compositional models extends from
| Model | Pose Accuracy @ pi/6 | |||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Elec. | Furn. | Hou. | Mus. | Spo. | Veh. | Work | |
| Oracle Model | ||||||||
| ResNet50-General | 53.6 | 49.2 | 52.4 | 45.8 | 26.0 | 65.2 | 56.5 | 58.5 |
| Open-Vocabulary Models | ||||||||
| ResNet50-General | 37.1 | 30.1 | 35.6 | 28.1 | 11.8 | 51.7 | 36.7 | 40.9 |
| SwinTrans-T-General | 35.8 | 30.9 | 34.3 | 26.1 | 12.2 | 46.2 | 34.4 | 39.2 |
| NMM-Sphere | 29.5 | 31.7 | 25.4 | 21.7 | 25.6 | 19.8 | 33.4 | 19.3 |
Task 3: Joint Image Clasification and Pose Estimation
Similar to task 2, we consider two types of models: (i) classification-based methods, and (ii) 3D compositional models. We adopt a 3D-aware classification accuracy, where a prediction is correct only if the predicted class label is correct and the predicted pose error is lower than a given threshold.
| Model | 3D-Aware Pose Accuracy @ pi/6 | |||||||
|---|---|---|---|---|---|---|---|---|
| Avg. | Elec. | Furn. | Hou. | Mus. | Spo. | Veh. | Work | |
| ResNet50-General | 50.9 | 60.0 | 67.2 | 43.0 | 43.8 | 27.7 | 64.1 | 33.8 |
| SwinTrans-T-General | 53.2 | 63.1 | 71.6 | 44.8 | 45.3 | 30.4 | 66.2 | 35.0 |
| LLaVA-pose |
49.1 | 58.0 | 65.6 | 41.6 | 41.0 | 26.1 | 61.8 | 32.1 |
| NOVUM |
56.2 | 59.6 | 65.6 | 52.5 | 41.9 | 30.6 | 69.6 | 39.3 |
| NMM-Sphere | 57.4 | 61.3 | 65.9 | 52.4 | 51.7 | 40.5 | 67.9 | 43.4 |
Discussion
Conclusion. In this paper we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D largely extends the number of rigid categories and object instances, as compared to previous datasets with 3D annotations. Moreover, ImageNet3D improves the quality of 3D annotations by annotating cross-category 3D alignment, and provides new types of annotations, such as object visual qualities and image captions interleaved with 3D information that enable new research problems. We provide baseline results on standard 3D tasks, as well as novel tasks such as probing of object-level 3D awareness and open-vocabulary pose estimation.
Experimental results show that with ImageNet3D, we can develop general-purpose models capable of inferring 3D information for a wide range of rigid categories. We also identify limitations of existing 3D models from our baseline experiments and discuss new problems and challenges for future studies.
Ethics. We follow the ethics guidelines and obtained Institutional Review Board (IRB) approvals prior to the start of our work. We described potential risks to the annotators, such as being exposed to inappropriate images from the ImageNet21k dataset